
MIT 协议 + 1M 上下文 + 原生 Agent 优化,MiMo-V2.5 试图解决的不仅是算力成本问题,更是企业私有化部署和复杂工作流落地的信任与效率门槛。
在 2026 年 4 月底的大模型开源圈,小米 MiMo-V2.5 系列的发布并没有像以往那样仅仅停留在参数规模的比拼上。当 MiMo-V2.5-Pro 在 Artificial Analysis 榜单上登顶全球开源大模型第一,并在 ClawEval 等 Agent 专项评测中超越 DeepSeek V4-Pro 和 Kimi K2.6 时,行业关注的重点开始转移:为什么一个消费电子巨头要如此激进地开源其最强模型?
从公开资料来看,MiMo-V2.5 并非传统意义上“通用能力更强一点”的大模型迭代,而是一次针对 Agent(智能体)场景 的全链路重构。它通过 HySparse 混合稀疏注意力架构解决了长上下文推理的成本痛点,通过 MIT 协议消除了企业商用的法律顾虑,并通过与 OpenClaw、Hermes 等主流框架的深度适配,试图成为下一代 AI 应用的基础底座。
这篇文章将从技术路径、商业价值、竞品差异和生态意图四个维度,拆解 MiMo-V2.5 到底想做什么,以及它对开发者和企业意味着什么。
一、 为什么切中 Agent 场景,而不只是“更聪明”的聊天机器人?
过去两年,大模型的竞争焦点主要集中在通用问答、逻辑推理和代码生成上。但到了 2026 年,随着 Agent 应用的爆发,行业发现了一个新问题:模型很聪明,但干不了长活。
在真实的 Agent 工作流中,模型需要执行数百甚至上千轮的工具调用(Tool Use),处理长达百万 Token 的项目文档或代码库,并在长周期任务中保持逻辑不跑偏。传统通用大模型在这种场景下往往面临两个瓶颈:
长上下文成本高且慢:处理 1M 上下文时,显存占用爆炸,推理延迟极高。
长程逻辑易断裂:超过几十轮交互后,模型容易忘记初始指令或陷入重复循环。
MiMo-V2.5 的设计逻辑明显是为了解决这两个痛点。
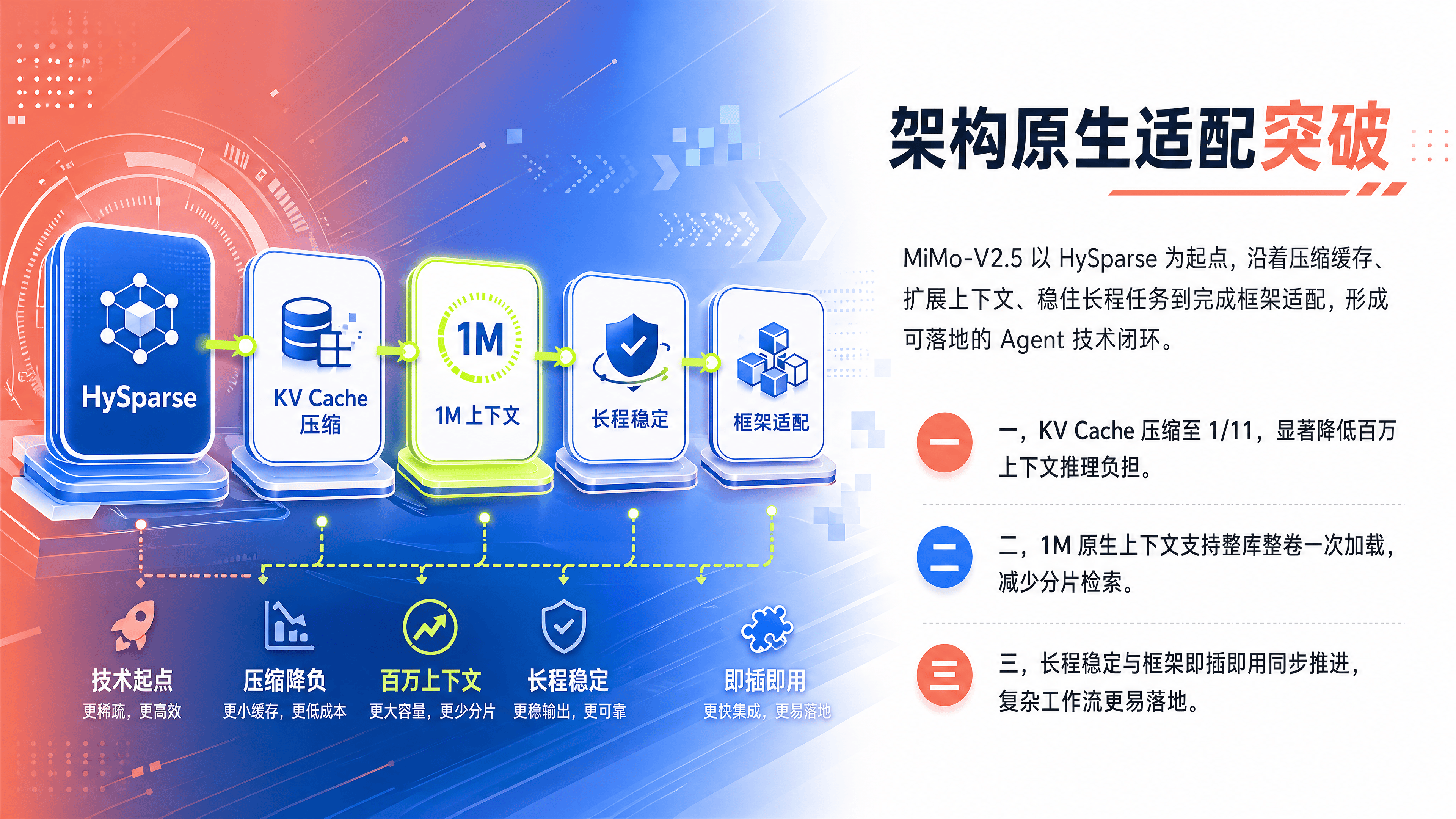
1. 架构原生适配:HySparse 混合稀疏注意力
MiMo-V2.5 系列采用了小米自研的 HySparse 混合稀疏注意力架构。与传统全注意力机制不同,HySparse仅保留极少层数的全注意力(Full Attention),其余层采用稀疏注意力(Sparse Attention)。
这种设计的核心优势在于:
KV Cache 大幅降低:在 1M 上下文场景下,KV 缓存占用降低至原来的 1/11,使得在消费级或中等算力集群上运行超长上下文成为可能。
推理效率提升:在保持长距离关键信息召回率接近 100% 的前提下,推理速度显著提升。对于需要频繁读取历史记忆的 Agent 来说,这意味着更快的响应和更低的 Token 消耗。
2. 训练流程专项优化:为“动手”而生
通用模型通常只在后期通过 SFT(监督微调)增加工具调用能力,这更像是一种“补丁”。而 MiMo-V2.5 从预训练阶段就引入了大量 Agent 轨迹数据,并进行了专项的强化学习(RL)。
公开测试数据显示,MiMo-V2.5-Pro 能够稳定完成单次近千轮工具调用的长程任务。在北大《编译原理》课程的 SysY 编译器开发项目中,MiMo-V2.5-Pro 仅用 4.3 小时、调用 672 次工具即完成全部开发,并在隐藏测试中取得满分。这种端到端的任务完成能力,是区分“聊天机器人”和“Agent 基座”的关键指标。
3. 生态前置适配:开箱即用
MiMo-V2.5 发布即完成了与 OpenClaw、OpenCode、KiloCode、Hermes 等全球主流 Agent 框架的官方适配。开发者无需编写复杂的中间件来兼容模型输出格式,只需在配置文件中指定模型名称即可接入。这种“模型+框架”的捆绑策略,极大降低了 Agent 开发的入门门槛。
二、 MIT 协议 + 1M 上下文:对企业私有化的真实意义
对于企业用户而言,选择开源模型而非闭源 API,核心考量通常是数据安全和成本控制。MiMo-V2.5 在这两点上给出了极具吸引力的组合拳。
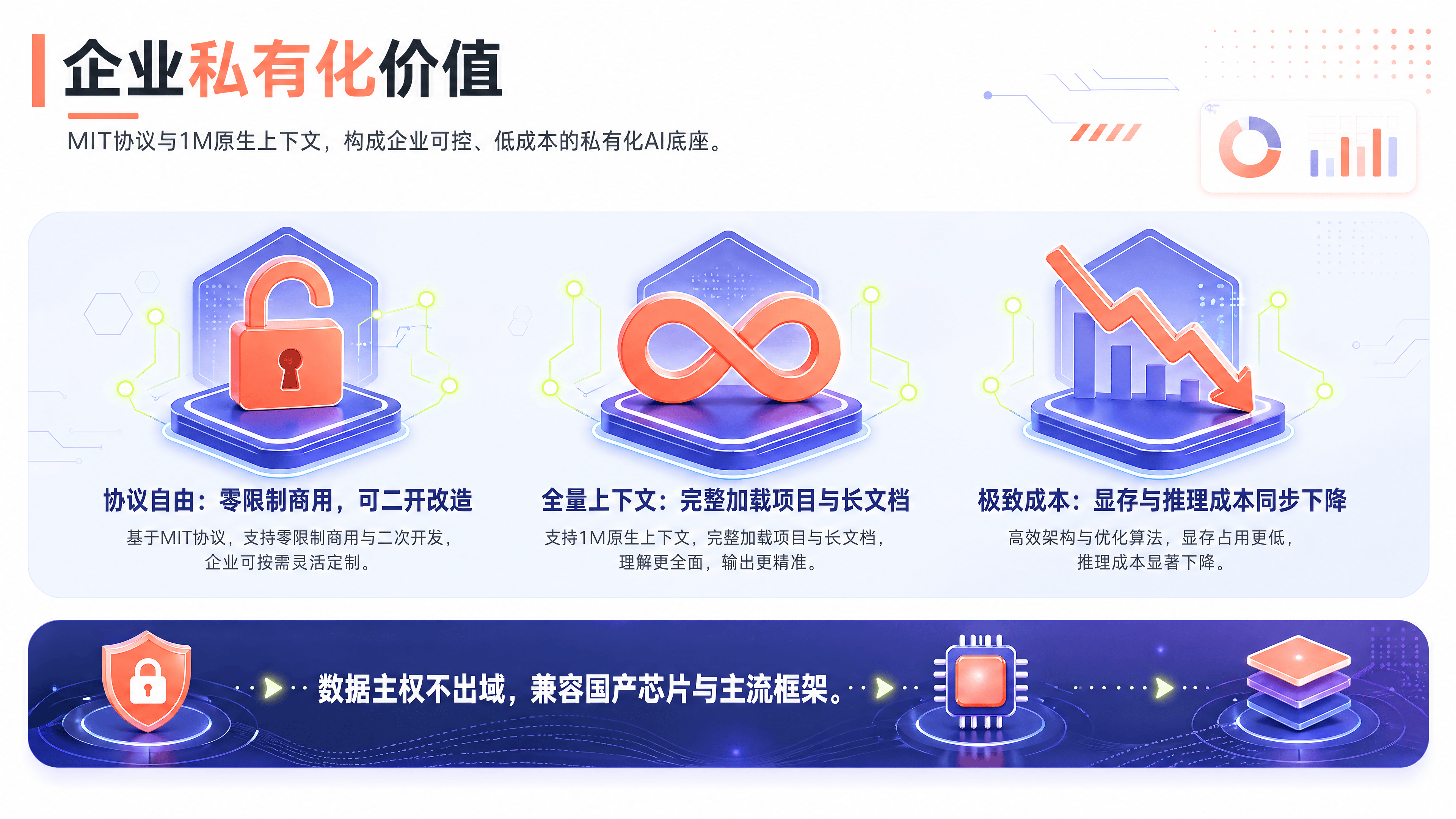
1. MIT 协议:最宽松的商用许可
MiMo-V2.5 系列采用 MIT 协议 开源。这是目前开源社区中最宽松、对商业最友好的协议之一。
无商用限制:企业可以将模型用于任何商业产品,无需向小米支付授权费或分成。
可二次开发:企业可以基于 MiMo-V2.5 进行继续预训练、微调(SFT/RLHF),甚至修改模型架构后重新发布。
数据主权:结合私有化部署,企业的所有业务数据无需出域,彻底规避了金融、法律、医疗等行业的数据合规风险。
相比之下,部分其他开源模型虽然允许商用,但可能在大规模部署时需要额外授权,或者禁止用于特定竞争领域。MIT 协议的纯粹性,使得 MiMo-V2.5 成为企业构建自有 AI 底座的理想选择。
2. 1M 上下文:消除“分片检索”的工程复杂度
1M Token 约等于 75 万汉字,或 10 万行代码,或 300 页 PDF 文档。在传统 RAG(检索增强生成)架构中,为了处理如此大量的数据,工程师需要将文档切分成小块,建立向量索引,再检索相关片段喂给模型。这个过程不仅复杂,还容易丢失全局上下文信息。
MiMo-V2.5 的 1M 原生上下文能力,允许企业一次性加载整个项目代码库、全套合同文件或完整会话历史。
代码代理场景:模型可以直接理解整个项目的架构依赖关系,生成的代码更符合整体规范,减少因局部视野导致的 Bug。
文档工作流:在法律合规审查中,模型可以同时对比数十份关联合同,发现跨文档的逻辑矛盾,而不仅仅是单段落的语义分析。
长程记忆:在客服或陪伴型 Agent 中,模型可以记住用户数月前的偏好和对话细节,提供更具连续性的服务。
3. 成本优势:百万亿 Token 激励计划
除了模型本身的低推理成本(得益于 HySparse 架构),小米还推出了 MiMo Orbit 计划,在一个月内发放总计 100 万亿 Token 的免费额度。对于初创团队和中小企业来说,这几乎意味着在验证阶段可以零成本使用顶级 Agent 模型。即使后续转为付费,其 API 定价也仅为国际闭源旗舰模型的 1/5,且取消了长上下文的倍率收费,夜间还有额外优惠。
三、 与 DeepSeek / Kimi 同类路线相比,差异点在哪?
2026 年的开源大模型市场,DeepSeek V4、Kimi K2.6 和 MiMo-V2.5 构成了第一梯队。它们都支持 1M 上下文,都强调 Agent 能力,但侧重点截然不同。
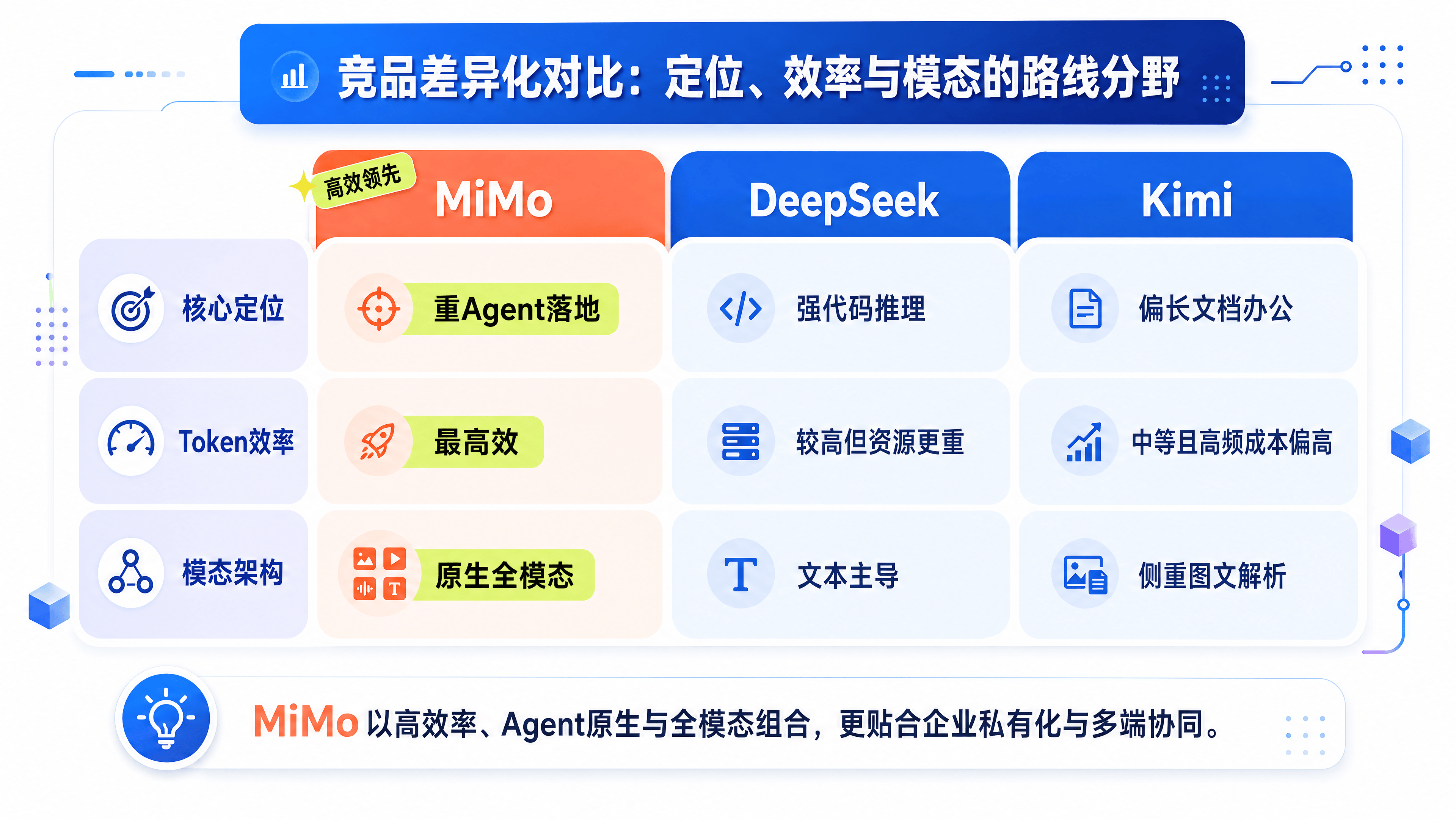
| 维度 | MiMo-V2.5-Pro | DeepSeek-V4-Pro | Kimi K2.6 |
|---|---|---|---|
| 核心定位 | Agent 原生优先,全场景覆盖 | 代码与推理优先,通用性强 | 长文档检索优先,办公场景强 |
| 参数规模 | 总参 1T,激活 42B (MoE) | 总参 1.6T,激活 49B (MoE) | 70B (密集参数) |
| Token 效率 | 极高,相同任务消耗更少 | 高,但略低于 MiMo | 中等,长文本检索精准但成本高 |
| 模态支持 | 原生全模态 (Pro+基础版组合) | 主要聚焦文本,多模态需外挂 | 多模态支持较好,但侧重图文 |
| 硬件适配 | 首日适配国产芯片 (平头哥、燧原等) | 适配主流 GPU,国产芯片跟进中 | 适配较少,主要依赖云端 |
| 生态资源 | 背靠小米硬件生态 + 开源框架深度绑定 | 强大的开发者社区 + 代码生态 | 月之暗面自身产品生态 (Kimi Chat) |
关键差异解读:
效率 vs. 规模: DeepSeek V4 通过更大的参数规模(1.6T)换取了极强的通用推理和代码能力,适合对智力上限要求极高的场景。而 MiMo-V2.5 更注重单位 Token 的效率,在相同的 Agent 任务完成率下,MiMo 消耗的 Token 更少,推理速度更快。对于需要高频调用的企业级 Agent 应用,MiMo 的 TCO(总拥有成本)可能更低。
全模态原生 vs. 文本主导: MiMo-V2.5 基础版是原生全模态模型,支持文本、图像、音频、视频的统一输入和理解。这意味着它可以作为智能家居、车载系统等需要多感官交互场景的统一大脑。相比之下,DeepSeek 和 Kimi 在多模态上的整合度稍弱,更多是通过外部模块实现。
国产芯片适配的“Day-0”策略: MiMo-V2.5 在开源首日即完成了对平头哥、燧原、天数智芯等国产 AI 芯片的深度适配,并提供了优化的推理引擎。这对于受限于供应链或出于信创要求必须使用国产硬件的企业来说,是一个巨大的落地优势。DeepSeek 虽然也有适配,但在官方支持的即时性和优化深度上,MiMo 表现得更为激进。
四、 长上下文模型在真实场景中的价值验证
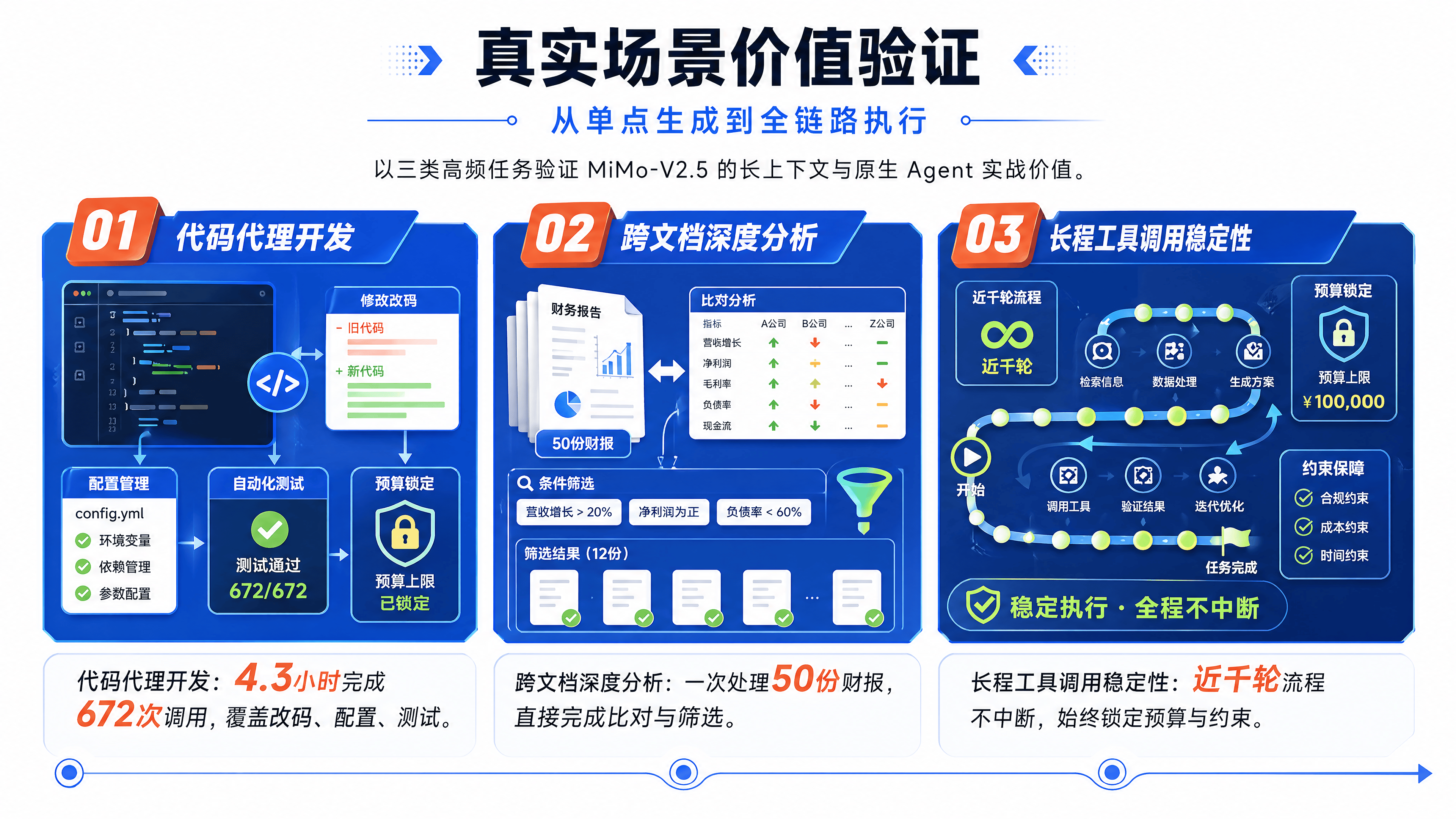
抛开评测榜单,MiMo-V2.5 的长上下文和 Agent 能力在以下几个真实场景中展现出了不可替代的价值:
1. 代码代理:从“写片段”到“做项目”
传统的代码助手只能根据当前文件生成函数或类。而基于 MiMo-V2.5-Pro 的代码 Agent,可以加载整个 Git 仓库的历史提交、Issue 讨论和文档。
- 案例:在某内部测试中,MiMo-V2.5-Pro 被要求为一个遗留 Java 项目添加新功能并修复兼容性问题。它不仅生成了新代码,还自动修改了相关的配置文件、更新了单元测试,并指出了潜在的性能瓶颈。这种全局视角是短上下文模型无法实现的。
2. 文档工作流:跨文档的综合分析
在金融和法律行业,分析师经常需要阅读数百份财报或合同。
场景:用户上传 50 份不同公司的年度财报,询问“哪些公司在研发投入占比上呈现连续三年增长,且净利润率高于行业平均?”
价值:MiMo-V2.5 可以一次性读取所有文档,直接在内存中进行交叉比对和计算,无需预先建立复杂的数据库索引。这不仅节省了建库时间,还避免了因切片不当导致的信息遗漏。
3. 复杂工具调用:长周期任务的稳定性
在自动化运维或电商运营场景中,Agent 可能需要执行长达数小时的串联任务。
挑战:传统模型在第 20 轮工具调用后,往往会忘记第一步的输出结果,或者混淆参数。
MiMo 的表现:得益于 1M 上下文和专项 RL 训练,MiMo-V2.5 能够在近千轮的调用中保持状态一致。例如,在自动策划一场电商大促活动中,它能记住最初设定的预算限制,并在后续的物料设计、投放计划制定中始终遵循这一约束,最终生成一份可执行的完整方案。
五、 小米做开源大模型,意在抢什么生态入口?
雷军宣布小米今年在 AI 领域投入超 160 亿元,并如此激进地开源 MiMo 系列,其战略意图显然不止于售卖 API。
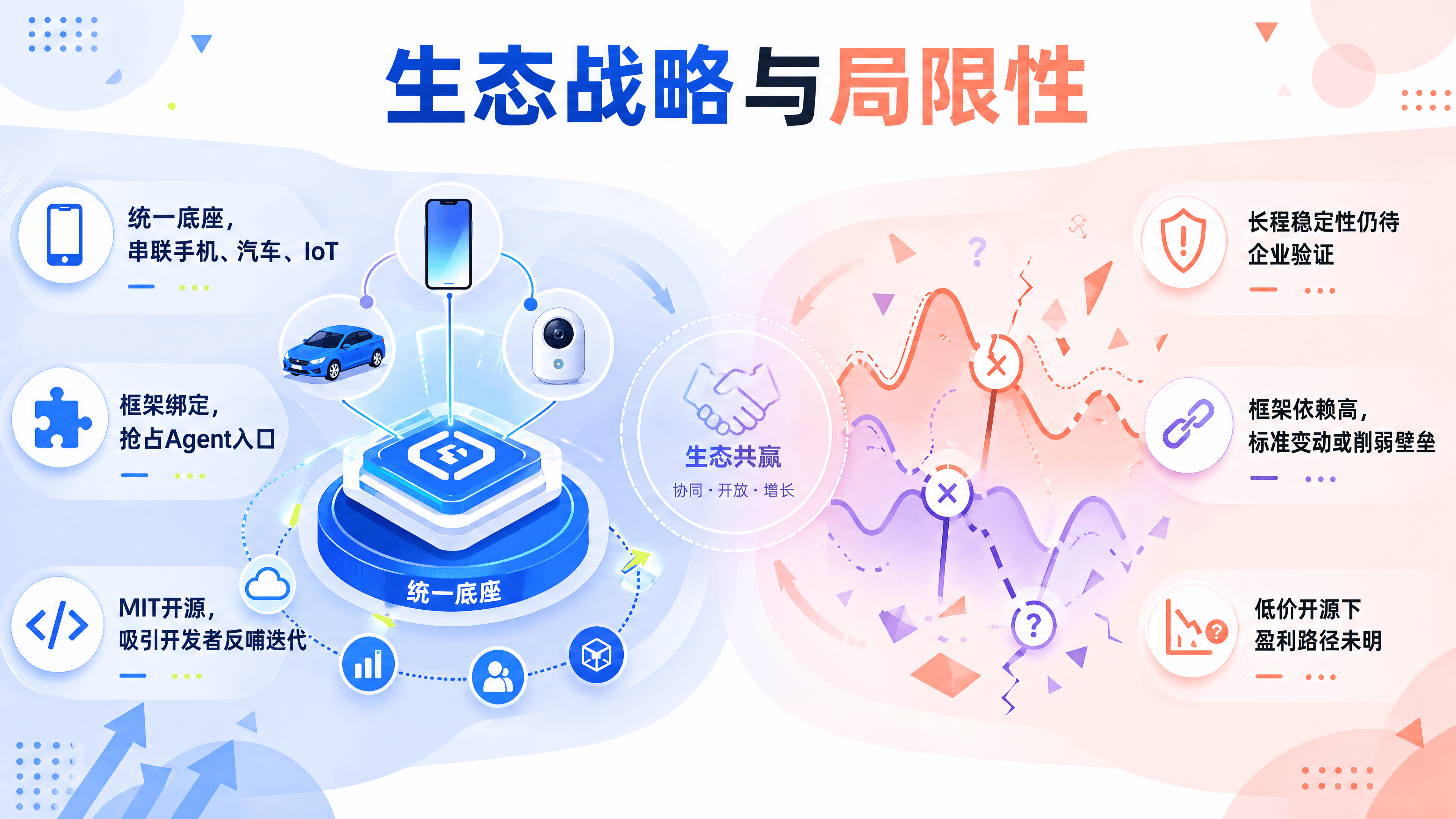
1. 统一硬件生态的 AI 底座
小米拥有手机、汽车、智能家居、可穿戴设备等庞大的硬件生态。这些设备需要一个统一的、高效的、能理解多模态信息的 AI 大脑。
- 端云协同:MiMo-V2.5 的高效架构使其更容易蒸馏到端侧设备,或与云端形成协同。例如,车载 Agent 可以同步手机的日程和家居状态,提供跨场景的主动服务。开源模型吸引了大量开发者为小米硬件开发专属 Agent 应用,丰富了硬件的软件生态。
2. 抢占 Agent 时代的基础设施话语权
在 PC 时代,Windows 是入口;在移动互联网时代,iOS 和 Android 是入口。在 AI Agent 时代,基础模型+开发框架可能成为新的入口。
- 通过开源 MiMo 并深度绑定 OpenClaw、Hermes 等框架,小米希望让全球开发者习惯使用 MiMo 作为默认基座。一旦生态形成,小米就从一家硬件公司转变为 AI 基础设施服务商,其影响力将延伸至企业级服务市场。
3. 吸引人才与技术反哺
开源是吸引顶级 AI 人才的最佳广告。罗福莉团队的加入以及 MiMo 系列的快速迭代,显示了小米在 AI 核心技术上的决心。开源社区的反饋和贡献也将反过来促进小米内部技术的进步,形成良性循环。
六、 局限性与后续观察
尽管 MiMo-V2.5 表现亮眼,但作为第三方观察者,仍需指出其存在的局限性和不确定性:
极端长上下文的稳定性仍需验证:虽然官方宣称支持 1M 上下文,但在极其复杂的逻辑推理或多文档交叉验证场景中,模型是否会出现“中间迷失”现象,仍需要更多真实企业案例的长期验证。
生态依赖风险:MiMo 的优势很大程度上依赖于与特定 Agent 框架的深度适配。如果未来开源框架格局发生变化,或者出现更通用的标准,MiMo 的适配优势可能会被削弱。
商业化闭环的挑战:虽然 MIT 协议有利于推广,但如何从海量的免费用户和低成本 API 使用中实现可持续的商业回报,仍是小米需要解决的问题。目前看来,硬件生态的增值可能是主要的变现路径,但这需要时间。
结语
MiMo-V2.5 的开源,标志着大模型竞争从“拼参数”进入了“拼场景、拼效率、拼生态”的新阶段。它不仅仅是一个性能强劲的开源模型,更是小米向 AI Agent 时代投出的一张重磅入场券。
对于开发者而言,MiMo-V2.5 提供了一个低成本、高自由度、原生适配 Agent 的开发基座;对于企业而言,它提供了一条数据可控、成本可观的私有化 AI 落地路径。至于它能否真正撼动 DeepSeek 和 Kimi 的地位,并成为小米硬件生态的强力引擎,接下来的半年里,我们将看到更多真实的应用案例给出答案。
参考资料


