
从“能调用工具”到“可控执行”,RAGFlow 0.25 的 Agent 沙箱升级,标志着开源 RAG 引擎正式补齐了企业级落地的最后一块拼图。
在很长一段时间里,开源 RAG(检索增强生成)领域的竞争焦点主要集中在“解析精度”和“召回率”上。谁能更准确地从复杂的 PDF、Excel 或扫描件中提取信息,谁就能赢得开发者的青睐。RAGFlow 正是凭借其在深度文档理解上的优势,在这一赛道中建立了差异化壁垒。
然而,随着 AI 应用从简单的“问答机器人”向具备自主规划、工具调用能力的“Agent(智能体)”演进,一个新的痛点浮出水面:如何确保 Agent 在执行代码、调用外部 API 或操作数据时的安全性与可控性?
2026 年 4 月发布的 RAGFlow 0.25 版本,给出了它的答案。这次更新并非简单的功能堆砌,而是通过解析管道标准化、Agent 沙箱隔离和用户级记忆系统三大核心升级,试图解决从数据输入质量到执行安全,再到交互连续性的全链路问题。对于正在评估是否升级的企业团队而言,理解这背后的逻辑比关注具体参数更重要。

一、 为什么 RAG 平台开始强调 Agent Sandbox?
在 RAGFlow 0.25 之前,许多开源 RAG 平台虽然支持 Agent 编排,但其执行环境往往是“裸奔”的。这意味着,当 Agent 被要求执行一段 Python 代码来分析数据,或者调用一个内部 API 查询订单状态时,这些操作直接运行在宿主服务器或容器环境中。
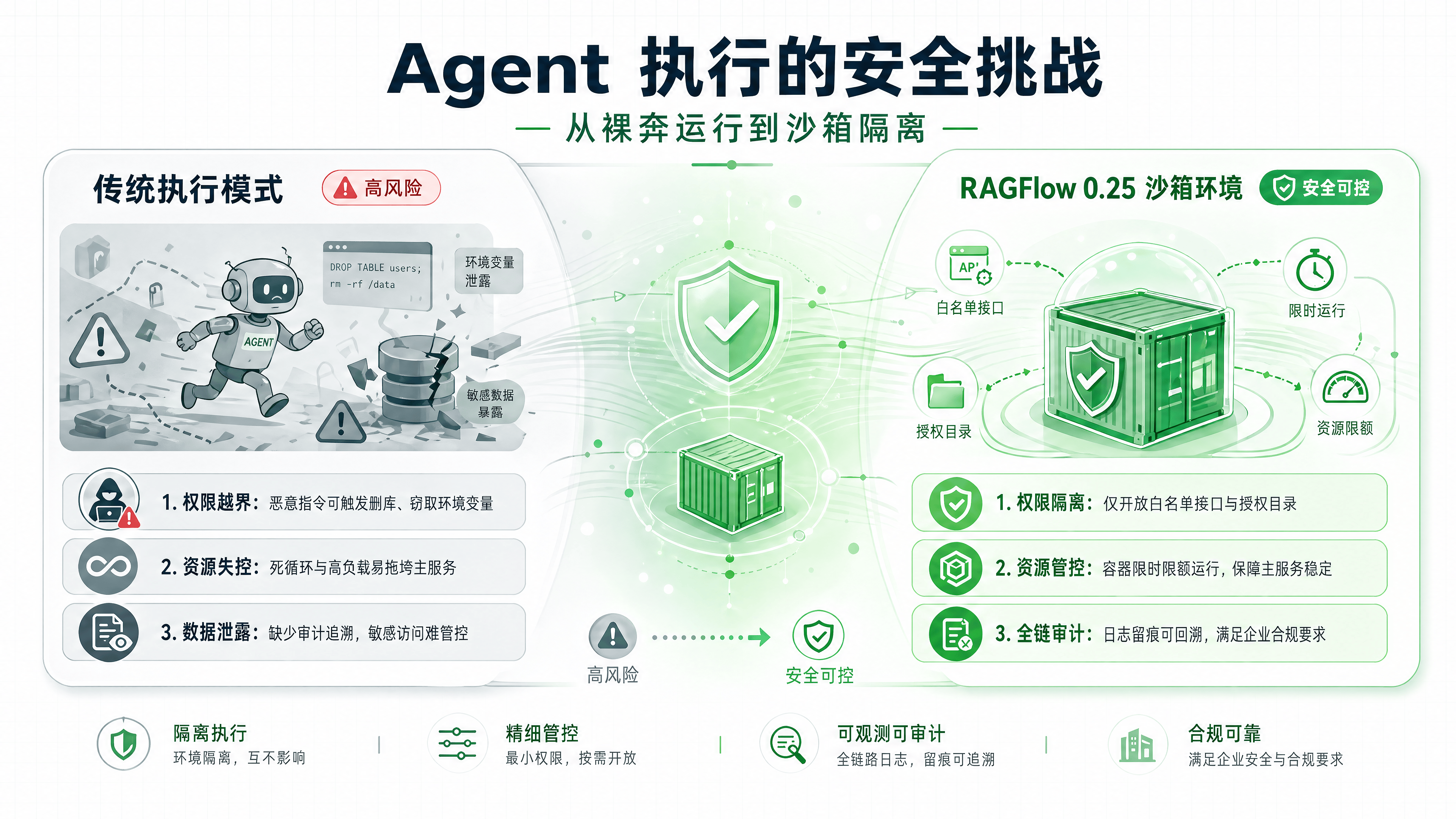
这种模式在演示场景下没有问题,但在企业生产环境中存在巨大风险:
权限越界:恶意构造的 Prompt 可能诱导 Agent 执行删除文件、窃取环境变量等危险操作。
资源不可控:一段死循环代码可能耗尽服务器 CPU 或内存,导致整个服务不可用。
数据泄露:Agent 可能在未授权的情况下访问敏感数据源。
RAGFlow 0.25 引入的 Agent 沙箱(Sandbox),本质上是为 Agent 构建了一个隔离的“无菌室”。在这个环境中,Agent 的代码执行、文件读写和网络请求都受到严格限制。这与近期 OpenAI Agents SDK 内置沙箱、PPIO 推出兼容 E2B 接口的 Agent 沙箱等行业动态一致,表明**“安全隔离执行”已成为 Agent 走向生产环境的标配基础设施**。
对于 RAGFlow 而言,这一升级意味着它不再仅仅是一个“知识库检索引擎”,而是一个具备全栈 Agentic RAG 能力的应用平台。它解决了企业用户“敢不敢让 Agent 动手”的核心顾虑。
二、 RAGFlow 0.25 的三个关键升级解析
1. 解析管道(Ingestion Pipeline):解决“垃圾进,垃圾出”
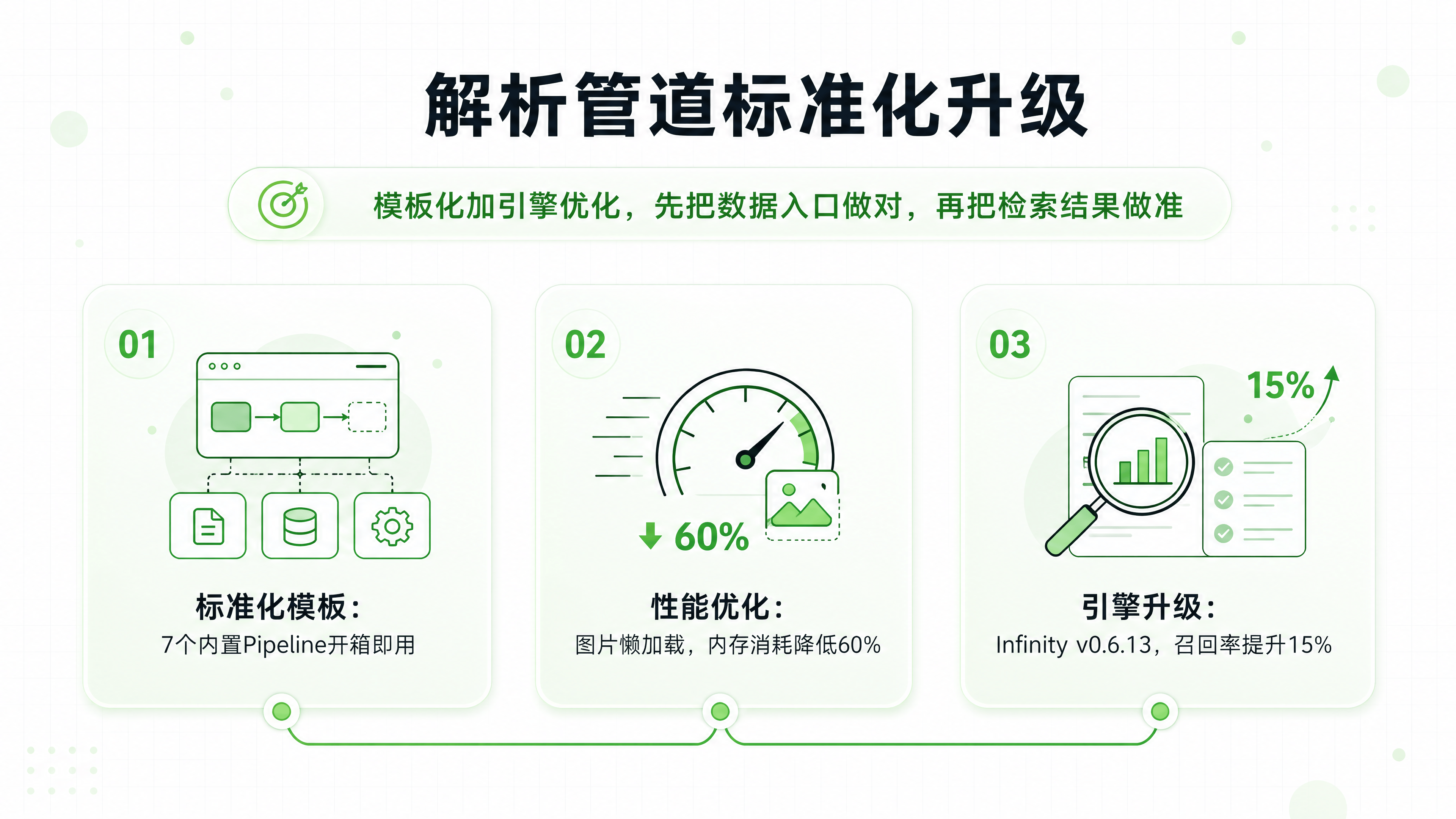
RAG 的效果上限取决于数据解析的质量。以往,面对不同格式(如多栏 PDF、复杂表格 Excel、图文混排 Word),用户往往需要手动调整解析策略,门槛较高且效果不稳定。
0.25 版本新增了 7 个内置 Pipeline 模板,并与 RAGFlow 核心的 DeepDoc 解析器深度对齐。
标准化流程:用户无需再为每种文档类型单独配置解析规则,只需选择对应的模板(如“财务报告专用”、“技术手册专用”),系统即可自动应用最优的分块、清洗和向量化策略。
性能优化:针对常见的 Docx 文档,优化了解析策略,支持图片懒加载(Lazy-load)。实测显示,在处理包含大量高清图片的大体积文档时,内存消耗可降低约 60%,显著减少了因内存溢出导致的解析失败。
检索引擎升级:底层的 Infinity 文档引擎升级至 v0.6.13,向后兼容的同时,检索召回率提升了约 15%。
价值判断:这一升级降低了知识库构建的技术门槛,让非算法背景的业务团队也能快速搭建高质量的知识库,解决了“解析效果依赖专家经验”的痛点。
2. Agent 沙箱与发布能力:从“实验”走向“生产”
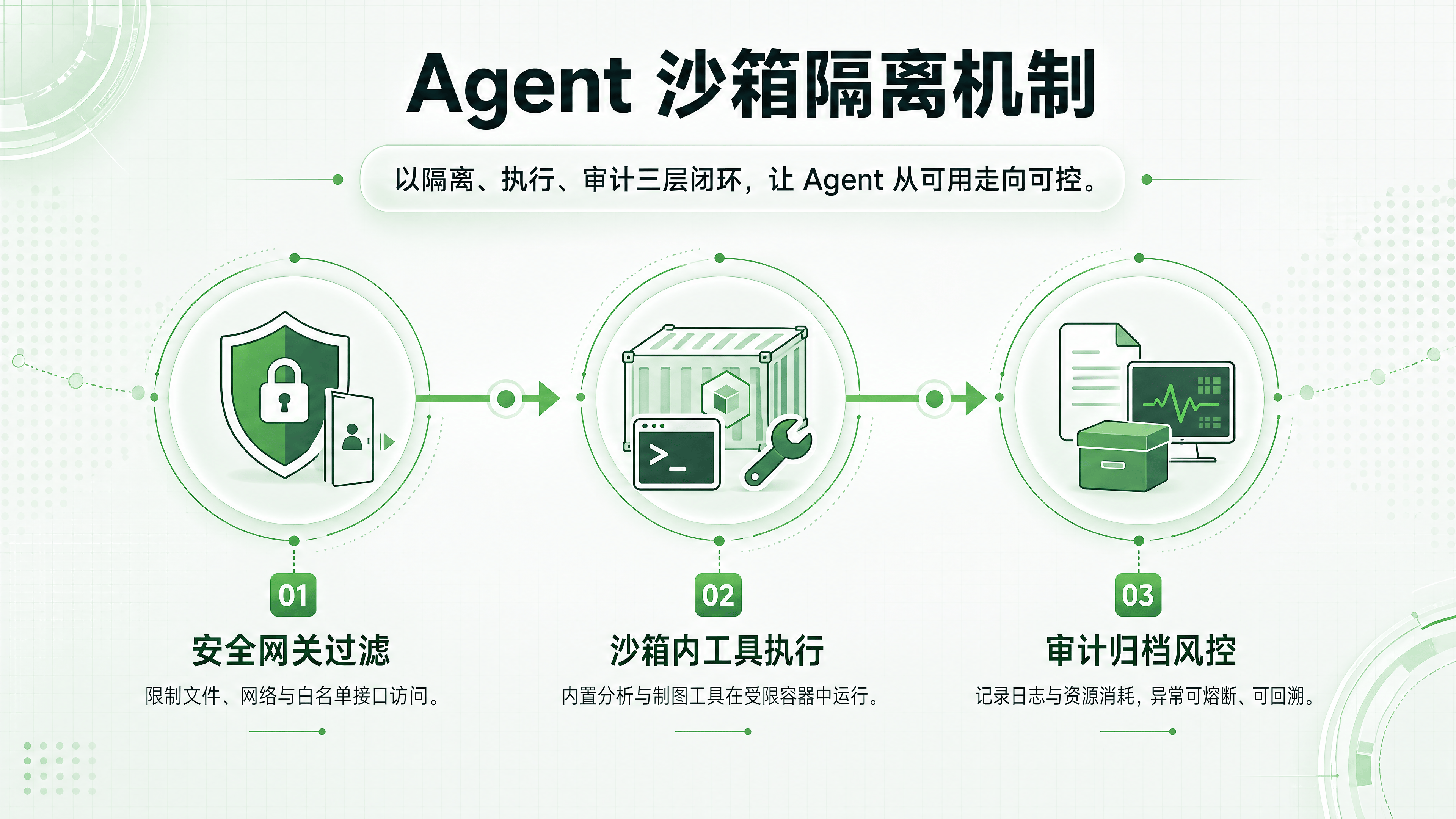
这是本次更新的重头戏。RAGFlow 0.25 引入了 Agent 发布能力,允许将编排好的 Agent一键部署到沙箱环境中独立运行。
隔离执行:沙箱环境默认限制文件系统访问权限和网络访问范围。Agent 只能在授权范围内使用工具(如仅允许读取特定目录、仅允许调用白名单内的 API)。
内置工具增强:为了配合沙箱执行,新版本内置了图表生成、数据分析等模板。Agent 可以在沙箱内直接完成数据处理和可视化输出,无需依赖外部不安全的执行环境。
可审计性:所有在沙箱内的执行过程均有日志记录,方便后续回溯和排查问题。
价值判断:这使得 RAGFlow 具备了承载复杂企业级任务的能力。例如,一个财务分析 Agent 可以在沙箱中安全地读取加密报表、执行计算脚本并生成图表,而无需担心数据泄露或系统崩溃。
3. 用户级记忆(User-level Memory):打破“会话孤岛”
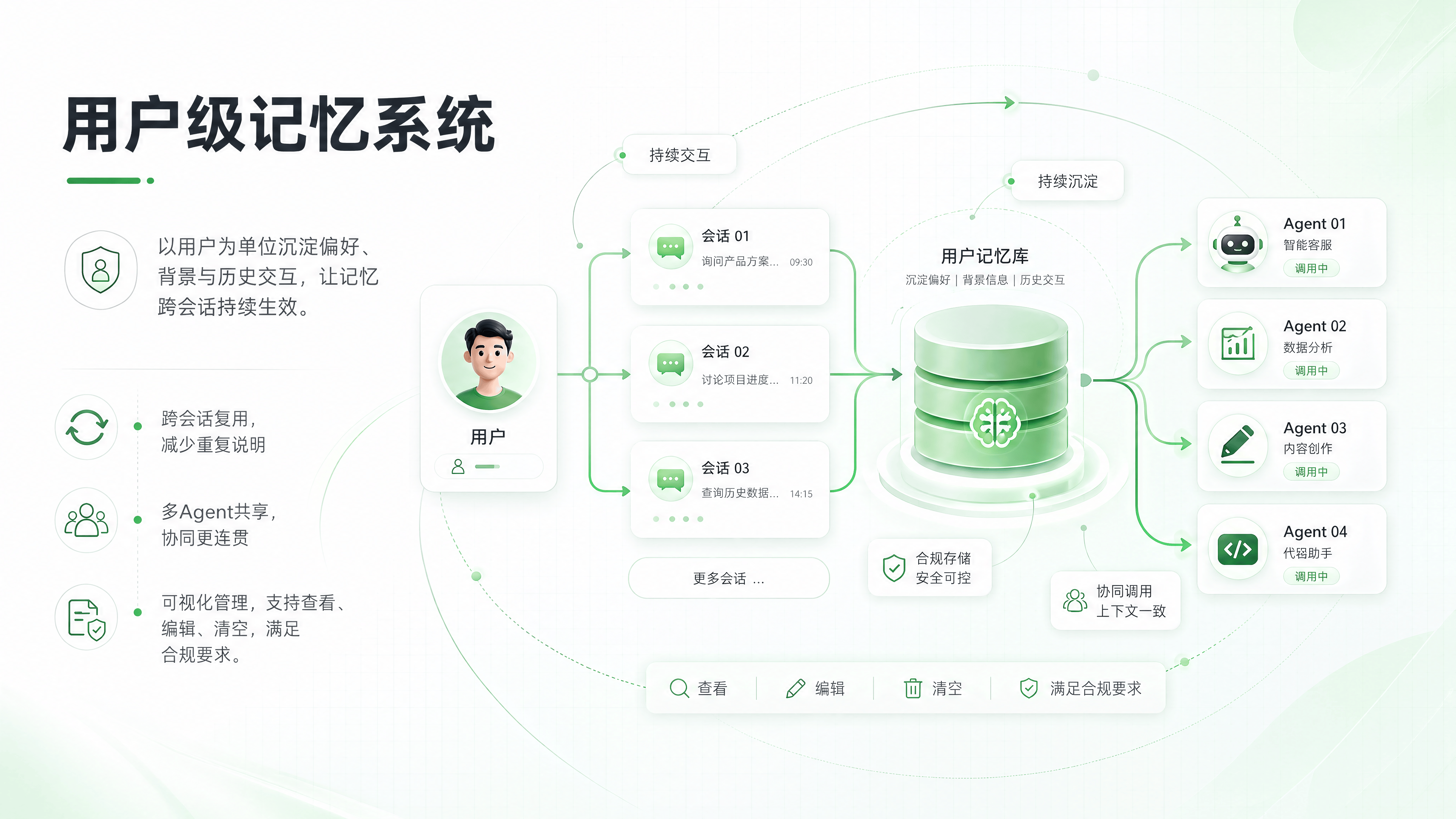
此前的 RAG 系统中,记忆通常仅限于单次会话(Session)。一旦用户关闭聊天窗口,之前的偏好、背景信息全部丢失,导致每次对话都需要重新交代背景,体验碎片化。
0.25 版本引入了 用户维度的长期记忆存储:
跨会话复用:系统会自动沉淀用户的对话偏好、历史查询记录和业务场景特征。
上下文共享:在不同的 Agent 或不同的会话中,只要属于同一用户,记忆即可共享。例如,用户在“客服 Agent”中提到的“我是 VIP 客户”,在“销售 Agent”中也能被识别并利用。
合规控制:支持手动编辑和删除记忆,满足 GDPR 等数据合规要求。
价值判断:这一功能让 Agent 从“一次性问答机器”进化为“懂你的助手”,显著提升了多轮交互的自然度和效率,是构建个性化 AI 应用的关键基石。
三、 把 RAGFlow 0.25 放进实际工作流
为了更直观地理解这些升级如何串联,我们可以设想一个**“企业智能数据分析”**的真实场景:
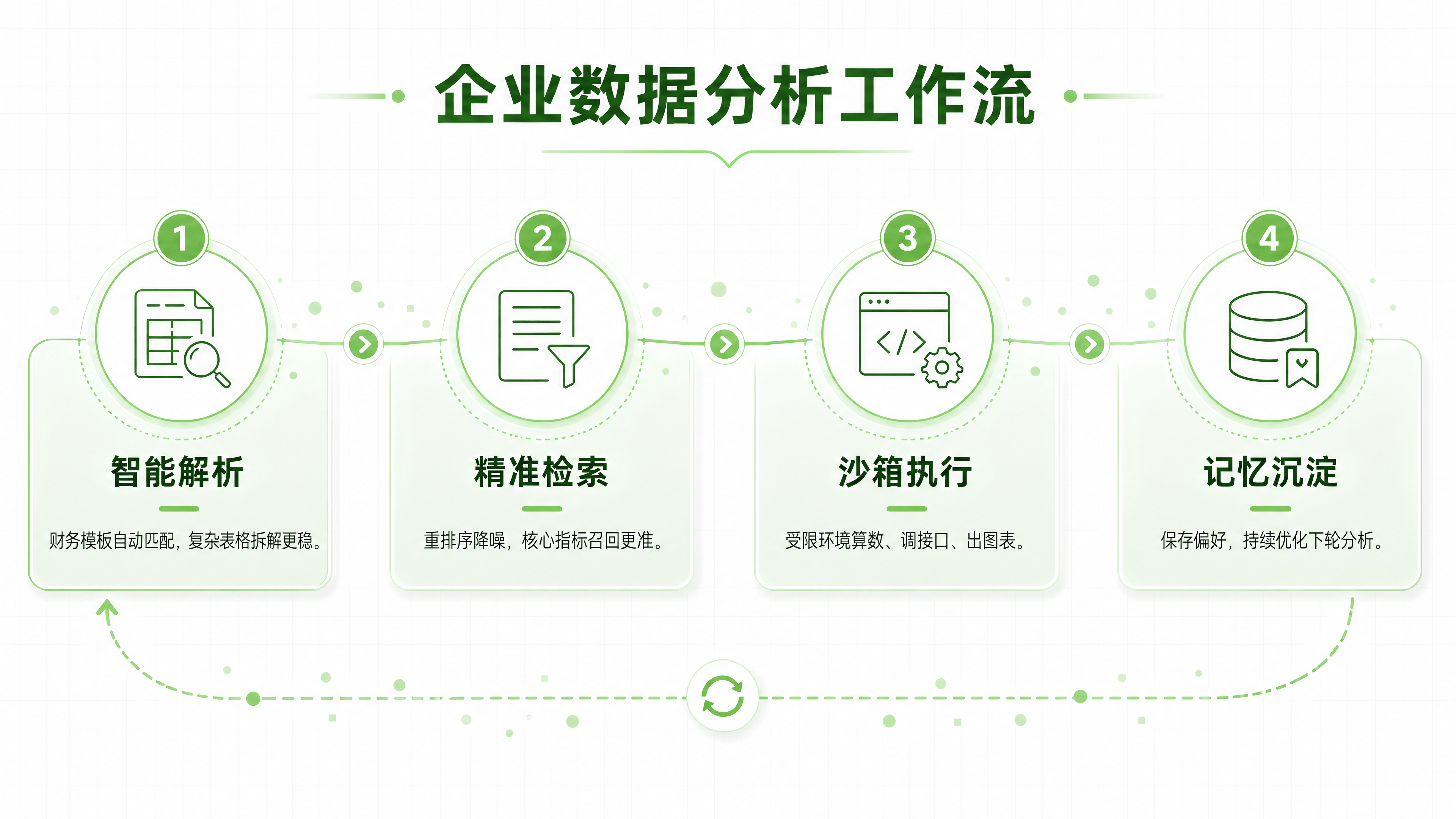
文档解析阶段: 用户上传一份包含复杂表格和图表的季度财务报告(PDF/Excel)。系统自动匹配“财务报告”Pipeline 模板,DeepDoc 精准提取表格结构和关键指标,Infinity 引擎完成向量化存储。相比旧版本,解析速度更快,且内存占用更低。
检索增强阶段: 用户提问:“对比上个季度,本季度的净利润变化原因是什么?” 系统召回相关的财务片段,经过重排序后,作为上下文提供给 Agent。由于 Infinity 引擎的升级,召回的相关性更高,减少了无关信息的干扰。
Agent 编排与沙箱执行: Agent 接收到任务,规划出以下步骤:
调用知识库获取具体数值。
在沙箱中执行 Python 代码,计算环比增长率。
调用内部 API 获取同期的市场舆情数据(沙箱限制仅允许访问该特定 API)。
生成对比图表。
整个过程在隔离的沙箱中运行,即使代码存在潜在风险,也不会影响主服务器。执行日志被完整记录,供管理员审计。
记忆沉淀与反馈: 用户对生成的图表风格提出修改意见:“下次请用深蓝色系。” 这一偏好被存入用户级记忆。下一次用户再次要求生成图表时,Agent 会自动应用深蓝色系,无需重复指令。
四、 RAGFlow 0.25 适合谁升级?
并非所有用户都需要立即升级到 0.25。基于公开资料和功能特性,我们可以给出以下判断标准:
用户群体 | 建议升级场景 | 暂不需要升级场景 |
|---|---|---|
知识库运营团队 | 1. 面临大量多格式文档(尤其是复杂 PDF/Word)解析难题。2. 希望降低知识库构建门槛,使用开箱即用的模板。3. 现有版本在处理大文件时频繁出现内存溢出。 | 1. 仅处理纯文本或简单 Markdown 文档。2. 现有解析效果已完全满足需求,无性能瓶颈。 |
企业 AI 应用团队 | 1. 正在开发需要调用工具、执行代码的 Agent 应用。2. 对数据安全有严格要求,需要隔离执行环境。3. 需要 Agent 具备数据分析、图表生成等复杂能力。 | 1. 仅使用简单的知识库问答功能,不涉及 Agent 编排。2. 已有其他成熟的沙箱解决方案(如自建 E2B 环境)。 |
私有化部署团队 | 1. 希望在一个平台内解决 RAG + Agent 的全链路需求,避免拼接多个工具。2. 需要全栈可控、可审计的 AI 基础设施。3. 重视用户长期记忆带来的体验提升。 | 1. 现有系统架构稳定,迁移成本高。2. 对新版功能的兼容性持观望态度,等待更多社区验证。 |
五、 平台化信号:RAGFlow 的战略转向
与传统 RAG 工具相比,RAGFlow 0.25 的发布释放了一个明确的信号:RAG 平台正在从“单一检索组件”向“全栈 Agentic 基础设施”转型。
过去,开发者可能需要组合使用 RAGFlow(做检索)、Dify(做工作流编排)、E2B(做代码沙箱)等多个工具来构建一个完整的应用。这种拼接方案虽然灵活,但带来了维护成本高、数据流转复杂、安全性难以统一管控等问题。
RAGFlow 0.25 试图通过内置沙箱、记忆系统和标准化的解析管道,将这些能力整合到一个平台中。其核心竞争力在于:
RAG 能力的深度整合:依托其在文档解析和检索上的传统优势,确保 Agent 获取的知识是高质量的。
安全执行的闭环:通过沙箱解决 Agent 落地的最后一大障碍。
用户体验的连续性:通过用户级记忆,提升应用的智能化水平。
与 Dify 等通用型 LLMOps 平台相比,RAGFlow 的优势依然在于其对非结构化数据处理的深度。Dify 在工作流编排生态上更为成熟,但 RAGFlow 在“复杂文档解析 + 安全 Agent 执行”这一垂直组合上,形成了独特的差异化竞争力。
六、 局限性与后续观察
尽管 0.25 版本进步明显,但从第三方视角看,仍有一些不确定性值得观察:
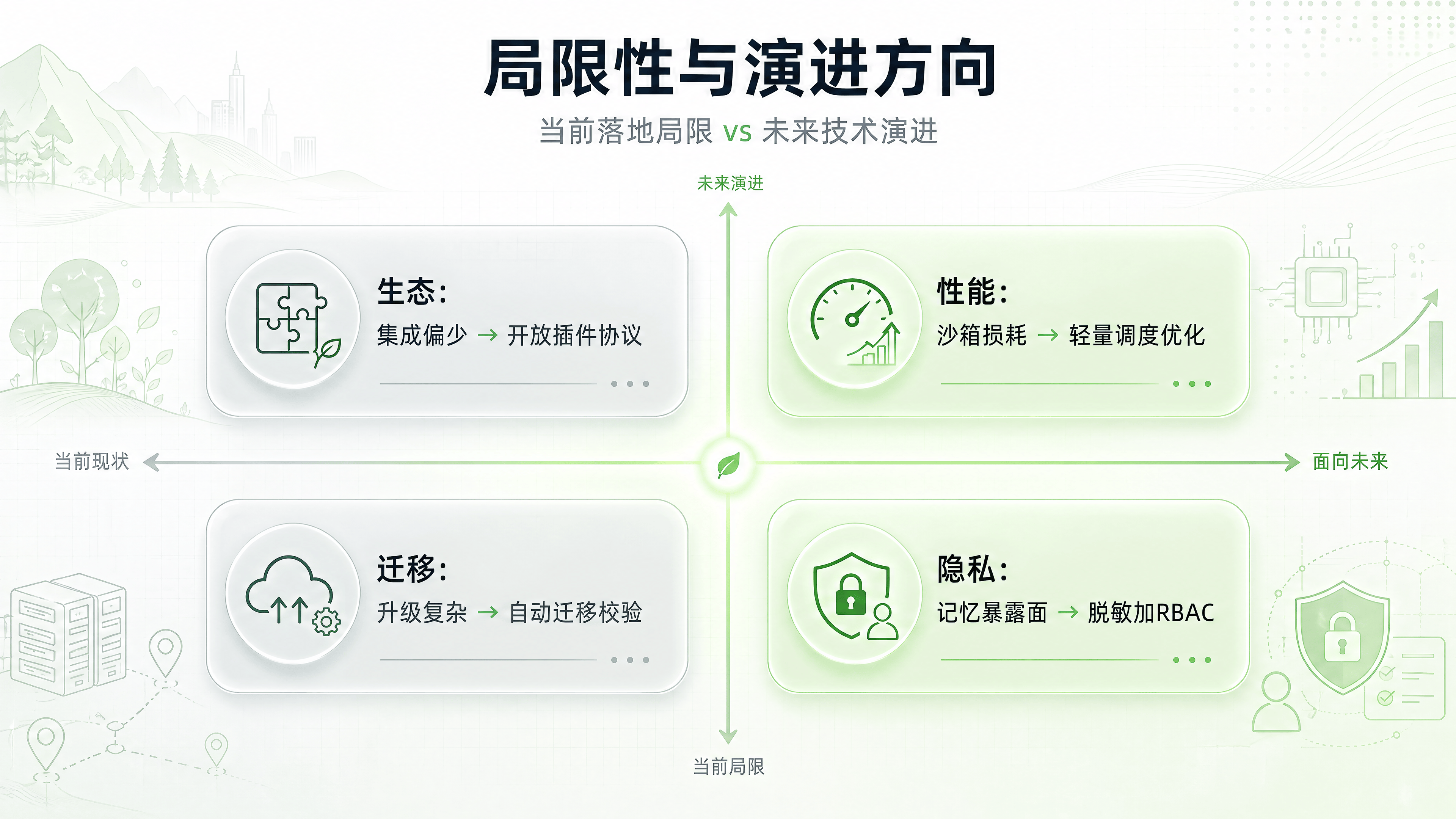
生态丰富度:相比 Dify 庞大的插件市场,RAGFlow 的内置工具和模板数量仍有差距。沙箱内支持的第三方工具集成程度,将直接影响其适用场景的广度。
沙箱性能开销:隔离环境必然带来一定的性能损耗。在高并发场景下,沙箱的启动速度、资源占用以及最大并发支持能力,仍需更多生产案例验证。
迁移成本:对于旧版本用户,升级到 0.25 可能需要调整原有的 Agent 配置和解析策略。官方提供的迁移指南和社区支持力度,将是影响升级意愿的重要因素。
记忆系统的隐私边界:用户级记忆虽然提升了体验,但也引入了隐私泄露的风险。如何在便捷性与隐私保护之间取得平衡,需要更细致的权限控制和脱敏机制。
结语
RAGFlow 0.25 的升级,不仅仅是一次功能迭代,更是开源 RAG 领域进入“Agent 原生”阶段的一个缩影。它表明,未来的 RAG 平台竞争,将不再局限于检索准确率的小数点后几位,而是扩展到数据处理的自动化程度、Agent 执行的安全性以及用户交互的智能化水平。
对于企业而言,如果正在寻找一个能够同时解决“复杂文档解析”和“安全 Agent 执行”的一站式方案,RAGFlow 0.25 无疑是一个值得重点评估的选项。但对于仅需要简单问答功能的场景,或许保持现状或选择更轻量的工具仍是更经济的选择。
接下来,值得观察的是 RAGFlow 是否会进一步开放沙箱的自定义扩展接口,以及社区能否围绕新的 Pipeline 模板和 Agent 能力,涌现出更多行业级的最佳实践。
参考资料


