
DeepSeek V4 最值得讨论的地方,不是它有没有“全面超过闭源模型”,而是它把 1M 上下文、工具调用、Thinking Mode 和开源权重放进了一套更便宜的使用路径里。
如果只是把 DeepSeek V4 当成一次常规模型升级,很容易漏掉它真正有变化的部分。
过去一年多,大模型厂商都在讲长上下文、代码能力、Agent 和推理增强。问题是,这些能力在真实使用里经常被成本、吞吐、部署难度和接口兼容性拦住。模型可以读一百万 token,不代表普通用户、开发者和企业真的敢把一百万 token 塞进去反复跑;模型会写代码,也不代表它能稳定接入 Claude Code、OpenCode 这类长程 Agent 工作流;模型开源,也不等于个人开发者可以轻松在本地完整跑起来。
DeepSeek V4 的看点正好在这些缝隙里。

2026 年 4 月 24 日,DeepSeek 发布 V4 系列预览版,包含 DeepSeek-V4-Pro 和 DeepSeek-V4-Flash 两个 MoE 模型。两者都支持 1M tokens 上下文,最大输出最高 384K tokens,并已经在 Web、App 和 API 上可用,同时在 Hugging Face 发布权重。V4-Pro 是更强调能力上限的版本,总参数约 1.6T,每 token 激活 49B 参数;V4-Flash 则是更偏成本和速度的版本,总参数约 284B,激活 13B 参数。
这组数字很容易让人兴奋,但更值得拆开看的是:DeepSeek 并没有只发一个“最大模型”,而是把 Pro 和 Flash 分成了两个明确档位。前者面向复杂推理、长程代码、Agent 任务,后者面向高频调用、日常对话、摘要、路由和轻量工作流。对开发者和企业来说,这比单纯比较“谁的参数更大”更实际,因为真实系统里很少所有请求都用最贵模型跑到底。

从 V3、R1 到 V4:DeepSeek 的主线没有变,但重心变了
DeepSeek 在 V3 和 R1 阶段建立起来的标签很清楚:开源权重、低成本、高性能、强推理。V3 让更多开发者开始认真对待国产开源 MoE 模型,R1 又把推理模型和低价 API 的话题推到了全球范围。
到了 V4,DeepSeek 仍然延续效率路线,但目标不再只是“同等能力更便宜”。V4 的产品语言明显更靠近 Agent 和长上下文:1M context 成为 DeepSeek 官方服务默认能力,API 支持 OpenAI ChatCompletions 和 Anthropic 格式,模型支持 Thinking / Non-Thinking 双模式,并提供 JSON Output、Tool Calls、Chat Prefix Completion Beta、FIM Completion Beta 等能力。

这几个点放在一起看,指向的是更复杂的任务执行,而不是单轮问答。
普通聊天场景里,1M 上下文可能显得有点过剩。但在 Agentic Coding、长文档分析、代码库理解、企业知识库、合同审阅、投研材料整理、医学指南比对这类场景里,模型“能一次看多少东西”直接决定工作流能不能简化。过去常见做法是先切片、检索、拼 prompt,再靠 RAG 补上下文;现在如果长上下文成本足够低,很多流程会更倾向于把更多原始材料直接放进模型视野里,再用检索和引用机制做校验。
这并不意味着 RAG 会消失。长上下文解决的是模型一次能读多少,RAG 解决的是资料如何更新、如何引用、如何权限隔离、如何审计。企业场景里,两者大概率会并存。但 1M context 如果变成默认能力,开发者设计应用时的假设会改变:以前要尽量少喂材料,现在可以更大胆地把完整任务现场交给模型。
Pro 和 Flash 的分层,比“一个旗舰模型”更接近真实需求
DeepSeek V4 系列目前最核心的两款模型是:
| 模型 | 总参数 | 激活参数 | 上下文 | 最大输出 | 定位 |
|---|---|---|---|---|---|
| DeepSeek-V4-Pro | 1.6T | 49B | 1M tokens | 最高 384K tokens | 能力上限、复杂推理、Agentic Coding |
| DeepSeek-V4-Flash | 284B | 13B | 1M tokens | 最高 384K tokens | 高频调用、低成本、轻量任务 |
MoE 架构的意义在这里很直接:模型可以保留更大的总参数容量,但每次推理只激活部分专家。V4-Pro 的 1.6T 总参数听起来很夸张,真正决定单次推理计算量的是 49B 激活参数;V4-Flash 则进一步把激活规模压到 13B,用来换速度和成本。

这也是 DeepSeek V4 和很多“只做旗舰叙事”的模型不同的地方。一个面向真实业务的 AI 系统通常会同时存在几类请求:
用户随手问答、摘要、翻译、改写;
后台批量处理、标签生成、路由判断;
长文档阅读、复杂检索增强问答;
代码库分析、生成补丁、跑测试、修复错误;
多轮 Agent 任务,持续调用工具并保留上下文。
这些请求不应该全部用同一个成本档位解决。Flash 更像系统里的默认工作马,适合大量常规请求;Pro 则更适合少量高价值、低容错的复杂任务。V4 的双模型路线,本质上是在帮开发者做成本分层。
当然,分层也带来一个现实问题:模型路由会变得重要。什么时候用 Flash,什么时候升级到 Pro,什么时候开启 Thinking Mode,什么时候用 non-thinking 以降低延迟和成本,这些都不是模型本身能完全替应用决定的。真正把 V4 用好的团队,可能不是把所有请求直接替换成 deepseek-v4-pro,而是围绕任务类型、失败重试、上下文长度、输出要求做一套调度策略。
1M 上下文不是噱头,前提是成本和 KV Cache 能压下来
长上下文一直是大模型能力展示里最容易“看起来强、用起来贵”的部分。传统注意力机制在长序列场景下会遇到计算和显存压力,KV Cache 也会随着上下文膨胀而变成推理成本的关键瓶颈。
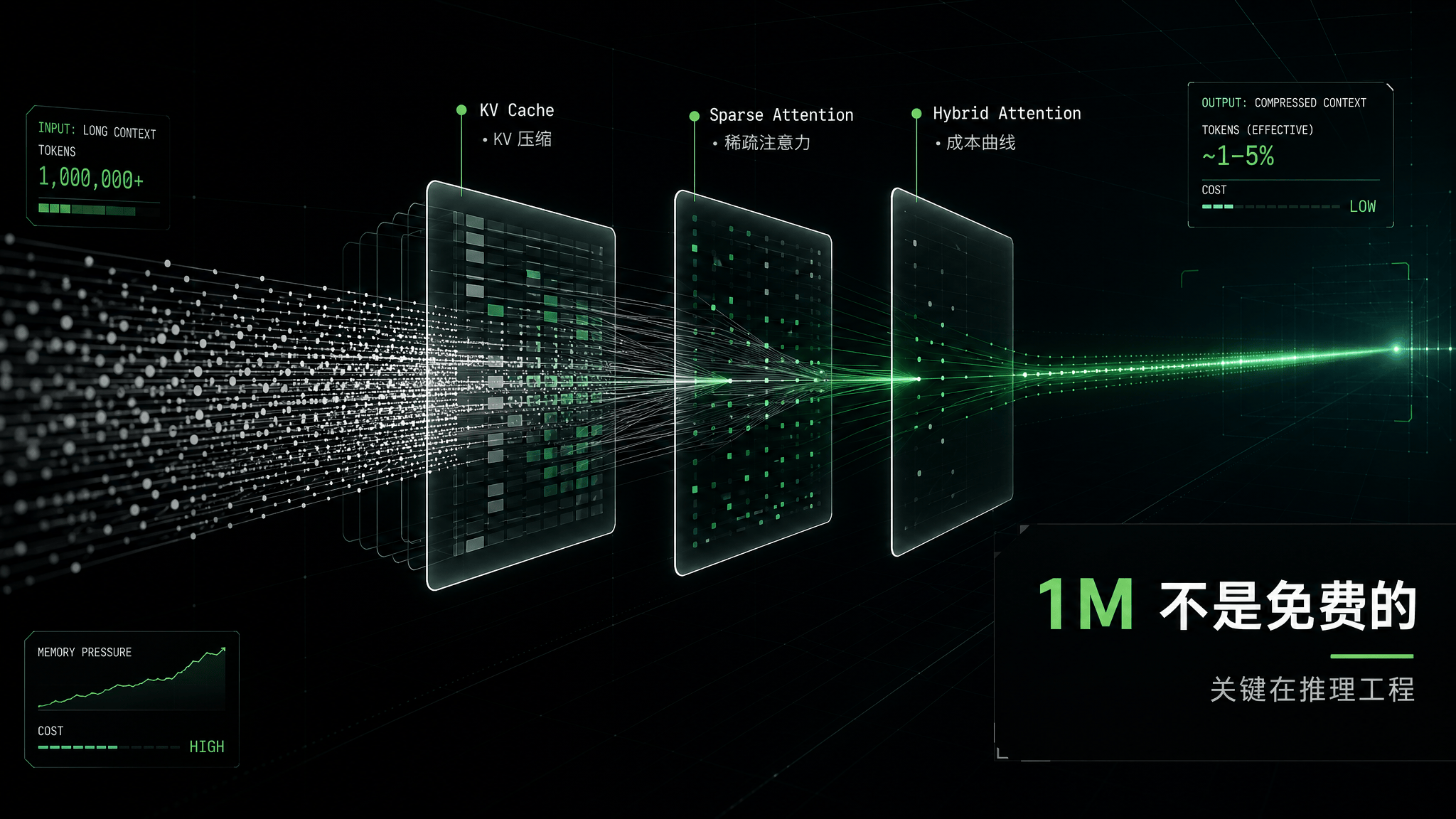
DeepSeek V4 的技术叙事集中在这里:通过混合注意力、压缩 KV Cache、稀疏注意力矩阵以及 DeepSeek Sparse Attention / Heavily Compressed Attention 等机制,降低 1M 上下文下的内存占用和计算开销。多家技术解读提到,V4 在 token 维度做压缩,并结合稀疏注意力,让百万上下文不再完全依赖“硬堆显存”。
NVIDIA 技术博客把 V4 的长上下文路径概括为 Hybrid Attention。SGLang / LMSYS 在 Day-0 支持文章里则提到,V4 服务栈需要适配 hybrid sparse-attention architecture、mHC 和 FP4 expert weights。这些词放在一起,说明 V4 的复杂度不只在模型权重本身,也在推理系统能不能正确、高效地支持这些结构。
技术细节可以不用展开到论文级别,但有几个结论对使用者很重要:
第一,1M 上下文如果要进入日常 API,不只是模型训练问题,更是推理工程问题。KV Cache 压缩、稀疏注意力、prefill/decode 分离、长上下文并行,都会影响实际延迟和价格。
第二,长上下文不是免费的。即使 V4 把单位成本压下来,百万 token 输入仍然意味着更长处理时间、更高缓存压力和更复杂的失败恢复。对企业应用来说,最好把长上下文当成一种高级能力,而不是每个请求都默认拉满。
第三,长上下文会改变 Agent 的可用性。Agentic Coding 场景里,模型要反复读代码、写文件、跑测试、理解错误,再继续修复。上下文越长,模型越有机会保留完整任务现场;上下文越贵,Agent 越容易被迫截断记忆。V4 的价值就在于它试图把这条成本曲线往下压。
API 怎么用:迁移成本低,但模型名和模式要留意
DeepSeek V4 的 API 接入路径对已经用过 OpenAI 格式的开发者比较友好。
API Base URL 仍然是:
TEXT
https://api.deepseek.com
Anthropic 格式入口是:
TEXT
https://api.deepseek.com/anthropic
模型名包括:
PLAINTEXT
deepseek-v4-flash
deepseek-v4-pro
DeepSeek 给出的迁移方式很明确:开发者可以保留原有 base_url,把 model 参数改为 deepseek-v4-pro 或 deepseek-v4-flash。这对已有应用很关键,因为很多项目不是不能换模型,而是不愿意大改 SDK、消息格式、工具调用封装和鉴权流程。
不过,开发者需要注意旧模型名的过渡。deepseek-chat 对应 deepseek-v4-flash 的 non-thinking mode,deepseek-reasoner 对应 deepseek-v4-flash 的 thinking mode,并且旧模型名未来会废弃。也就是说,如果一个项目还在用旧名称,短期可能还能跑,长期最好尽快切到 V4 的明确模型名和模式配置。
功能上,V4 支持 Thinking / Non-Thinking、JSON Output 和 Tool Calls。FIM Completion Beta 只支持 non-thinking 模式,这对代码补全类应用很重要。很多开发者容易默认“越强模式越好”,但 FIM 这类低延迟、结构化补全任务通常更看重响应速度和确定性,不一定适合开启完整推理模式。
本地部署相关的参数也有几个细节:Hugging Face 模型卡建议本地部署采样参数使用 temperature = 1.0, top_p = 1.0;Think Max reasoning mode 建议上下文窗口至少设置为 384K tokens。这里的提醒很实际——如果上下文窗口设置太小,模型虽然能跑,但并不代表跑的是 V4 想发挥的完整能力。
价格:Flash 是规模化入口,Pro 是高价值任务档位
DeepSeek V4 的价格仍然延续了 DeepSeek 一贯的成本竞争风格,但这次不是简单“全部低价”,而是分成 Flash 和 Pro 两个账本。
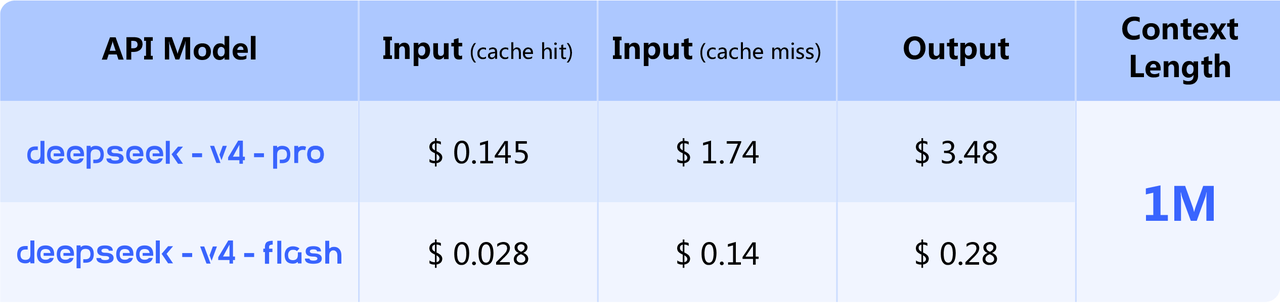
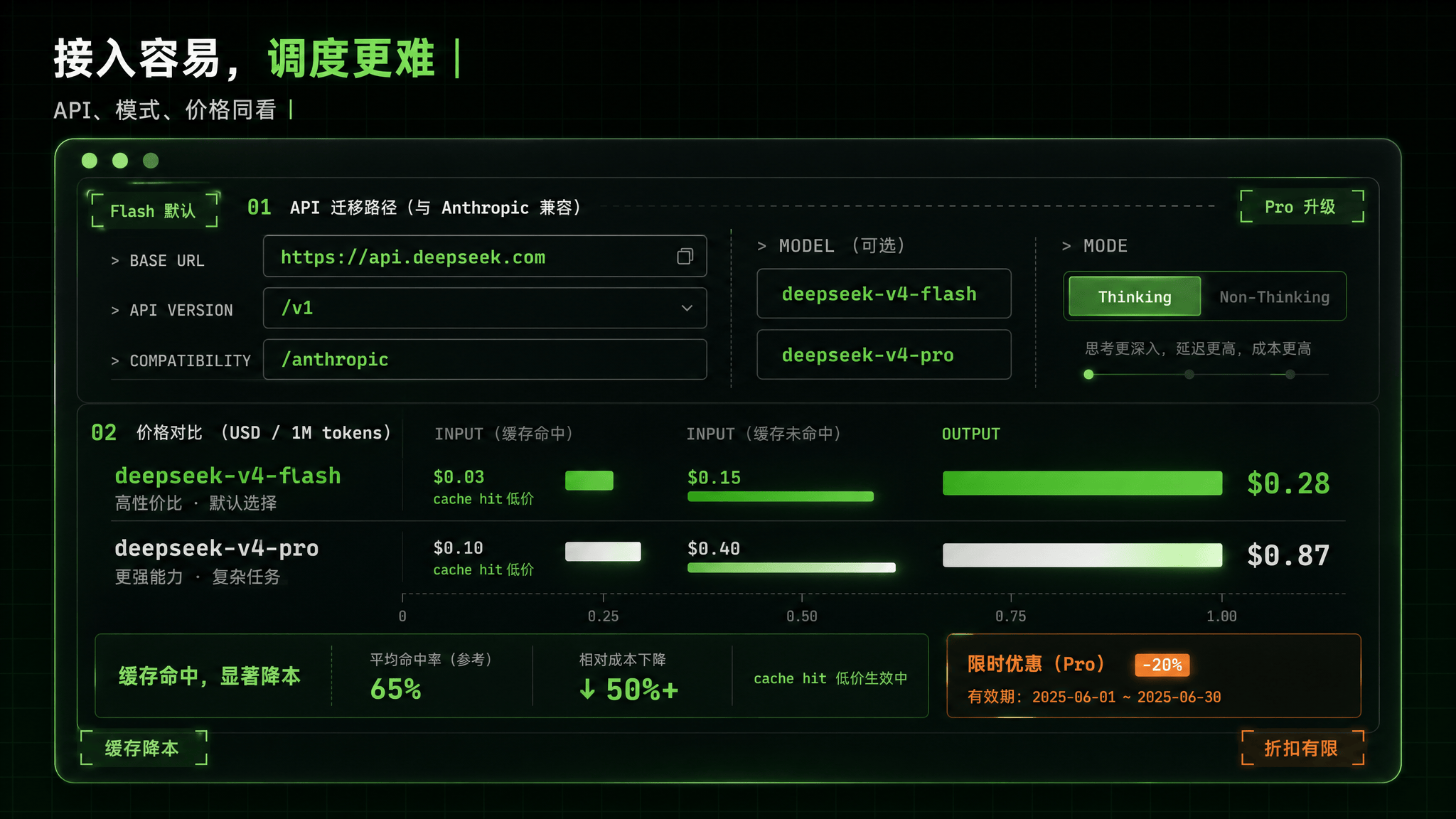
按每 1M tokens 计价:
| 模型 | 缓存命中输入 | 缓存未命中输入 | 输出 | 备注 |
|---|---|---|---|---|
| deepseek-v4-flash | $0.0028 | $0.14 | $0.28 | 常规定价 |
| deepseek-v4-pro | $0.003625 | $0.435 | $0.87 | 75% off 后价格 |
| deepseek-v4-pro 原价 | $0.0145 | $1.74 | $3.48 | 官方划线价 |
这里有两个地方值得单独看。
一个是 cache hit 输入价格。所有模型 cache hit 输入价格自 2026 年 4 月 26 日 12:15 UTC 起降至首发价的 1/10。长上下文应用里,如果大量历史上下文可以复用,缓存命中会直接影响成本结构。Agent、多轮文档问答、代码库分析都属于可能受益的场景。
另一个是 Pro 折扣有期限。deepseek-v4-pro 的 75% 折扣延长至 2026 年 5 月 31 日 15:59 UTC。DeepSeek 也保留调整价格的权利。换句话说,现在看到的 Pro 价格不能简单当作长期采购价。企业做成本测算时,应该分别按折扣价和原价估算,避免把限时价格写进长期商业模型。
这也解释了为什么 Flash 可能会承担更多真实流量。Pro 适合复杂任务,但如果业务每天有大量用户请求,Flash 的输入输出价格更容易支撑规模化调用。合理的做法是:Flash 处理常规任务,失败、复杂、长程或高价值请求再升级到 Pro。
开源权重已经给出,但“开源”不等于低门槛本地部署
DeepSeek V4 的权重主要发布在 Hugging Face Collection,而不是以 GitHub 仓库作为主要入口。Collection 包含四个条目:
DeepSeek-V4-Flash-Base
DeepSeek-V4-Flash
DeepSeek-V4-Pro-Base
DeepSeek-V4-Pro
模型卡标注为 Text Generation,许可证为 MIT。MIT License 对研究、二次开发、商业采用都比较友好,这也是 DeepSeek 对开发者生态保持吸引力的重要原因。
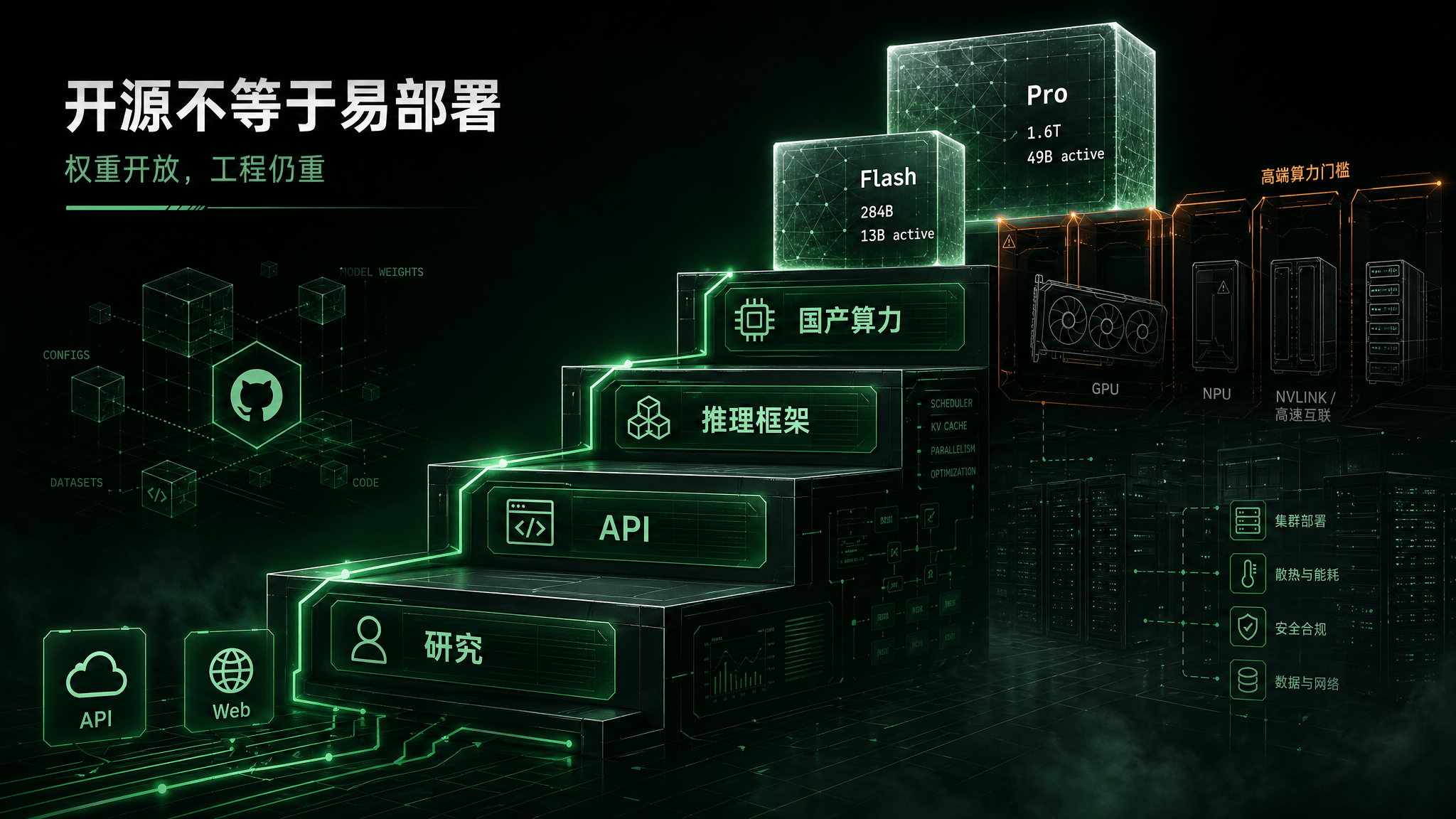
但需要把“权重开放”和“人人可跑”分开看。
V4-Pro 是 1.6T 总参数、49B 激活的 MoE 模型。即使 MoE 降低了单次激活计算量,完整部署仍然需要复杂的推理框架、高端 GPU / NPU 集群、长上下文并行、KV Cache 管理和权重格式适配。个人开发者可以下载模型卡、研究结构、调用 API,但完整本地部署 Pro 并不现实。V4-Flash 相对轻一些,但 284B 总参数仍然远超普通消费级设备舒适区。
Hugging Face 模型卡提到本地运行可参考仓库中的 inference folder,包括权重转换和交互式 chat demo。SGLang 文档提供了 DeepSeek-V4 专门 Cookbook,覆盖 low-latency、balanced、max-throughput、长上下文 cp / prefill context-parallel,以及 prefill / decode disaggregation,也就是 pd-disagg。这说明 V4 的部署不只是“启动一个模型服务”这么简单,而是需要按目标场景选择吞吐、延迟和上下文策略。
还有一个容易被忽略的点:SGLang 对 H200 GPU 部署提示应使用 sgl-project 下的 SGLang checkpoint,而不是默认 DeepSeek checkpoint。这类细节对生产部署很关键。模型权重、推理框架、checkpoint 格式、量化精度和注意力实现只要有一个环节不匹配,就可能出现性能不佳、显存爆掉或直接无法启动。
如果要概括 V4 的本地部署路径,可以这样理解:
研究者:优先看 Hugging Face 模型卡、技术报告和 Base 模型;
应用开发者:优先用 API 接入,验证功能和成本;
推理工程团队:看 SGLang / vLLM / NVIDIA 端点和对应 checkpoint;
国产算力团队:关注 AtomGit、昇腾、CANN 和算子优化实践;
普通用户:直接用 DeepSeek Web 或 App,没必要折腾本地部署。
Agentic Coding 是 V4 最容易落地的场景,但也最考验稳定性
V4 发布后,外界讨论最多的应用场景之一是 Agentic Coding。
这和普通“代码生成”不是一回事。过去 AI 写代码更多是补函数、解释报错、生成脚本。Agentic Coding 更像让模型接管一个较长流程:阅读项目、理解需求、规划修改、编辑多个文件、运行测试、根据报错继续修复,直到交付一个可运行结果。
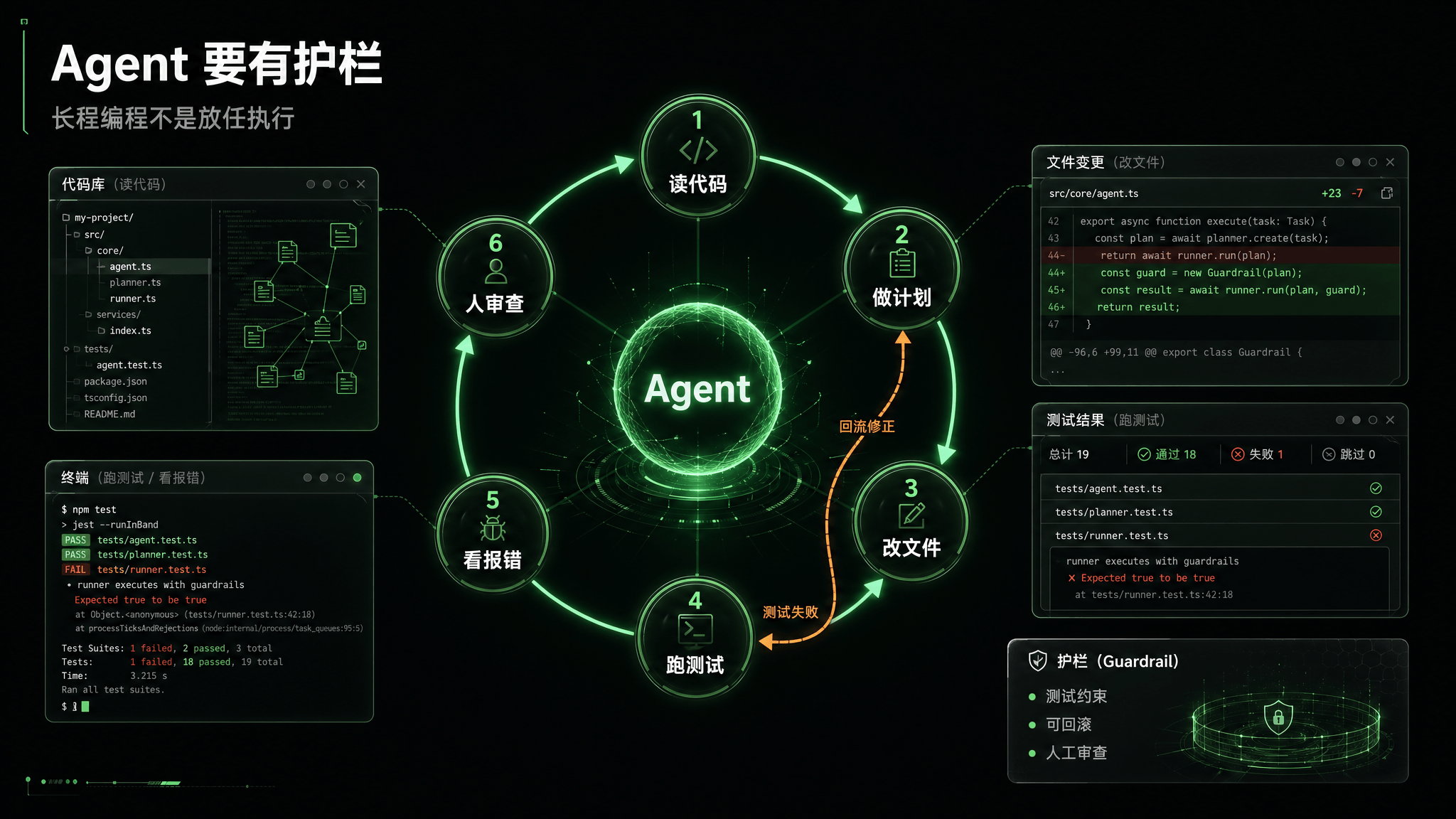
DeepSeek V4 在这类场景里有几个天然优势:
1M 上下文有利于读取更大的代码库和更多任务历史;
Tool Calls 让模型更容易接入文件系统、终端、测试工具;
Thinking Mode 适合复杂规划和多步调试;
OpenAI / Anthropic API 兼容降低了接入 Claude Code、OpenCode、OpenClaw 等 Agent 工具的难度;
Flash / Pro 分层可以降低大规模编程辅助工具的调用成本。
DeepSeek 称 V4 已与 Claude Code、OpenClaw、OpenCode 等主流 Agent 产品集成,并用于内部 agentic coding。媒体实测也提到,V4-Pro 在长程 agentic coding 中表现突出,能连续自主编程较长时间,体现出规划、自我纠错和工具调用能力。
但代码 Agent 也是最容易暴露模型问题的场景。模型只要在某一步误判依赖、误改文件、过度思考、陷入无效循环,后面的成本就会快速放大。第三方体验里已经出现过 V4-Pro 在部分 IMO 难题、简单问题或特定任务上死循环、错误回答、过度思考的反馈。这不是 DeepSeek 独有的问题,而是当前长程 Agent 的通病:模型越能自主行动,越需要外部约束、测试、回滚和人工审查。
所以 V4 在编程里的合理用法,不是完全替代工程师,而是接入一个有护栏的工作流。例如:
让模型先读代码库并输出修改计划;
对关键改动要求引用文件和行级理由;
小步提交,避免一次性大范围改动;
每轮改动后自动运行测试;
对失败测试让模型解释原因,而不是盲目重写;
最终由人审查 diff 和安全影响。
长上下文和低价 API 让这种工作流更可行,但不能取消工程纪律。
国产算力适配:这次不是边角新闻
DeepSeek V4 另一个重要信号是国产算力适配。
开放原子开源基金会称,AtomGit 平台为 DeepSeek-V4 昇腾适配版本首发平台,提供模型推理优化实践、Ascend C 融合算子优化,以及基于 CANN 的 TorchTitan-NPU + AutoFuse 训练优化实践。界面新闻也提到,V4 技术报告披露其在 NVIDIA GPU 与华为昇腾 NPU 两个平台验证了细粒度专家并行方案,相对非融合基线在通用推理任务中实现 1.50-1.73 倍加速,在延迟敏感场景中最高 1.96 倍加速。
这件事的意义不只是“支持国产芯片”四个字。
大模型能不能在一个硬件生态里跑得好,取决于很多底层细节:算子融合、通信开销、专家并行、KV Cache 管理、长上下文 prefill、decode 分离、量化格式、训练和推理框架适配。DeepSeek V4 这种 MoE + 长上下文 + 混合注意力的模型,对硬件和系统栈的压力更大。它如果能在昇腾、CANN、AtomGit 这条线上形成可复用实践,对政企、金融、教育、工业等强调本地化和数据安全的场景,会比单纯发布一个模型文件更有价值。
NVIDIA 也同步发布了围绕 Blackwell 和 GPU 加速端点构建 DeepSeek V4 的技术博客,并提到使用 SGLang、vLLM 和面向 Agent 工作流的构建路径。换句话说,V4 并不是“摆脱某个硬件生态”这么简单,而是进入多硬件、多推理框架、多服务形态同时适配的阶段。
这也说明大模型竞争正在从单模型能力变成系统能力。谁能让模型更便宜、更稳定、更容易部署到不同硬件,谁才更可能拿到企业长期使用。
性能评价要克制:开源第一梯队,不等于全面领先闭源
V4 发布后,很多标题会自然走向“比肩闭源”“开源最强”“挑战 GPT / Claude / Gemini”。这类说法需要拆开。
Hugging Face 模型卡给出的部分基准里,V4-Pro-Base 相比 V3.2-Base 有明显提升:
| Benchmark | DeepSeek-V3.2-Base | V4-Flash-Base | V4-Pro-Base |
|---|---|---|---|
| MMLU | 87.8 | 88.7 | 90.1 |
| MMLU-Pro | 65.5 | 68.3 | 73.5 |
| C-Eval | 90.4 | 92.1 | 93.1 |
| Simple-QA verified | 28.3 | 30.1 | 55.2 |
| FACTS Parametric | 27.1 | 33.9 | 62.6 |
这说明 V4-Pro 在知识、事实和通用能力上相对 V3.2 有实质提升,Flash 也在多数指标上超过 V3.2。但 Pro 和 Flash 的差距也很明显,尤其在事实知识和复杂知识类任务上。
Agentic Coding 方面,DeepSeek 的表述相对克制:V4-Pro 达到开源模型最佳水平,使用体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式,但仍与 Opus 4.6 思考模式存在差距。这个说法比“全面超过闭源”更可信,也更接近真实选型。
第三方测评则呈现分化。有的实测强调 V4-Pro 长程编程能力很强,有的榜单认为它进入开源第一梯队;也有开发者和媒体指出,它与最新顶级闭源模型仍有差距,综合排名并非所有榜单都领先 Kimi、GLM 或闭源模型。财新提到的第三方测评中,V4 在多项测评集平均准确率排名并不处于全球最前列,且输出速度和单次测试成本在某些比较里逊于 K2.6。
所以,对 V4 更稳妥的判断是:它是当前开源模型第一梯队的重要成员,在长上下文、成本、Agent 和开源权重上形成了很强组合;但它不是所有任务里的绝对第一,也不能简单替代 GPT、Claude、Gemini 的顶级版本。
企业选型尤其不能只看发布当天榜单。更实际的测试应该包括:
自己业务数据上的准确率和幻觉率;
长上下文输入下的稳定性;
工具调用成功率;
多轮 Agent 任务完成率;
失败后是否能自我纠错;
延迟、吞吐、限流和价格变化;
输出格式是否稳定;
安全、隐私和审计要求。
还有几个坑,最好在兴奋之前先看清
DeepSeek V4 确实值得关注,但也有一些容易被宣传话术盖住的问题。
最重要的是,多模态目前不能当作已确认能力。早期搜索结果和市场传闻里出现过“V4 原生多模态”的说法,但 DeepSeek 官方资料、NVIDIA 技术博客和 Hugging Face 模型卡都将 V4 标为 Text / Text Generation。至少在当前可验证资料里,V4 应按文本模型理解,不应把图片、音频、视频原生输入写成确定能力。
第二,Pro 服务吞吐可能受高端算力约束。复杂模型的 API 不是只看单价,还要看排队、限流、稳定性和高峰期可用性。财新和界面新闻都提到 Pro 模型服务吞吐受高端算力影响。对生产业务来说,模型再强,如果高峰期不可用,也需要备用模型和降级策略。
第三,Thinking Mode 不是所有任务都适合打开。简单问答、格式转换、低延迟补全和批处理任务,过度思考可能反而增加成本、延迟,甚至引发不必要的长输出。智东西实测里提到的“过度思考”和死循环,正好提醒开发者要按任务选择模式。
第四,本地部署门槛很高。MIT License 和 Hugging Face 权重给了研究和二次开发空间,但 V4-Pro 不是普通工作站能轻松完整部署的模型。即使使用 SGLang、vLLM 或国产算力适配,也需要专业推理工程能力。
第五,API 折扣不是永久价格。Pro 目前的 75% off 有明确截止时间,DeepSeek 也保留调价权利。商业应用做预算时,不能只按发布期价格估算。
谁适合现在尝试 DeepSeek V4
如果只是普通用户,DeepSeek Web 和 App 已经是最低门槛入口。V4 的价值主要体现在长文本理解、复杂问题推理、代码辅助和更长多轮对话上。普通聊天未必能明显感知 1M 上下文,但处理长 PDF、长报告、小说、合同、论文综述时会更有意义。
如果是独立开发者或小团队,优先从 API 开始,而不是本地部署。可以先用 Flash 承担默认请求,再把复杂任务切到 Pro。需要注意模型名迁移、Thinking / Non-Thinking 模式选择、缓存命中成本和输出格式稳定性。
如果是 AI 编程工具、Agent 工具或 IDE 插件开发者,V4 值得重点测试。它的长上下文、工具调用和 Anthropic API 兼容格式对 Agent 工具有实际意义。但测试重点不应只放在“能不能写代码”,而要看连续 30 分钟、60 分钟任务里能不能稳定规划、修改、运行测试和收敛。
如果是企业团队,V4 的吸引力在于成本和可控性。API 可以快速验证业务价值,开源权重和国产算力适配则提供了未来私有化或本地化的可能。但企业不能忽略幻觉、权限隔离、审计、数据合规、模型输出责任和供应商价格变化。
如果是研究者,V4-Pro / Flash 的 Base 模型、技术报告、MIT License 和 MoE 长上下文架构都值得研究。尤其是混合注意力、mHC、FP4 expert weights、长上下文效率和多硬件适配,都是比单纯跑分更有研究价值的部分。
暂时不适合直接上生产的情况也很明确:对稳定吞吐有极高要求但没有备用方案;对模型输出事实准确性要求极高但没有检索和审核;希望低成本本地跑完整 Pro;或者把早期折扣价格当作长期商业基础。
DeepSeek V4 的真正意义:不是终结闭源,而是降低长上下文和 Agent 的使用门槛
DeepSeek V4 不适合被简单写成“国产模型再次震撼全球”或者“全面超过闭源模型”。这种说法既不准确,也遮住了它真正有价值的地方。

它更像是 DeepSeek 从单个爆款模型走向模型服务、开源权重、Agent 工具、推理框架和硬件生态协同的一次关键更新。1M 上下文成为官方服务标配,Pro / Flash 分层降低了不同任务的选型成本,OpenAI 与 Anthropic API 兼容降低了迁移门槛,MIT License 继续扩大研究和二次开发空间,AtomGit / 昇腾、SGLang、NVIDIA 等生态适配则说明它不只是一个模型文件。
但 V4 仍然有边界。它是文本模型,不应被误写成已确认原生多模态;它在开源模型里很强,但并非所有第三方测评都领先;它的长上下文能力很有吸引力,但长上下文不等于事实可靠;它开源了权重,但本地部署尤其是 Pro 版本仍然是高门槛工程;它的 API 价格很有竞争力,但折扣和服务吞吐都有不确定性。
更合理的期待是:DeepSeek V4 会推动更多开发者和企业把百万上下文、Agentic Coding、工具调用和复杂推理放进真实工作流里,而不是只停留在演示视频和榜单截图。它未必终结闭源模型的领先位置,但会继续压低前沿能力的使用成本。
这可能才是 DeepSeek 一直最擅长的事情。
参考资料


